Why the Polls Don't Mean What You Think They Mean
There are three kinds of lies: lies, damned lies and statistics.
Benjamin Disraeli
With the elections less than two weeks away, many have already proclaimed Hillary Clinton as the winner. This is based on Clinton’s overwhelming dominance in the polls and election forecasts. I’d like to show that the race, based on what we know now, is much closer than what most of us think, in two very meaningful ways:
- We humans aren’t generally very good at interpreting the “forecast” numbers that are being presented to us.
- There are more systemic and structural ways than we’re aware of, in which the polls and forecasts, despite being very professionally executed, may end up incorrectly predicting the outcome.
Disclaimer: Please don’t take what follows to mean that I am making a prediction to the opposite of what most forecasts suggest. It is indeed likely, based on information we have now, that Hillary Clinton will win the election. Nor am I suggesting that the best forecasting methods out there are not well designed and executed. They are. (Nate Silver literally wrote the book on forecasting and I’m criticizing his system) The last thing to know is that I do have a strong preference for one candidate over the others, and that, combined with my neurotic nature, makes me more interested in convincing myself and you that the race is closer than it seems.
National Polls Are Meaningless, So Just Don’t
Let’s kill off one huge thing really quickly to begin, and that is the National Polls. 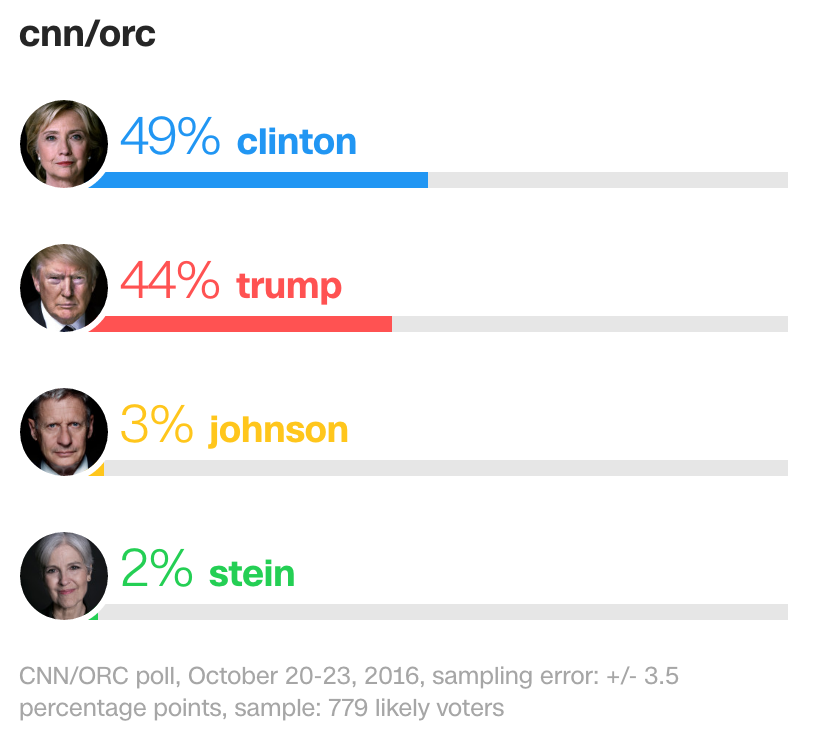 These are actually the “predictive” numbers that get the most airplay on traditional media, which isn’t great, because they have very little to do with how the Presidential Elections actually work. Presidential Elections use an electoral college where the winner in each state gets all the state’s electoral votes (with only two exceptions), a quantity proportional to each state’s population. Getting the most votes nationwide is not what gets you elected and so, nationwide polls are an obviously flawed method of forecasting the outcome of the election.
These are actually the “predictive” numbers that get the most airplay on traditional media, which isn’t great, because they have very little to do with how the Presidential Elections actually work. Presidential Elections use an electoral college where the winner in each state gets all the state’s electoral votes (with only two exceptions), a quantity proportional to each state’s population. Getting the most votes nationwide is not what gets you elected and so, nationwide polls are an obviously flawed method of forecasting the outcome of the election.
State by state simulation is better
Luckily, there’s a better system, popularized by Nate Silver of FiveThirtyEight and now used by many major news outlets like the New York Times.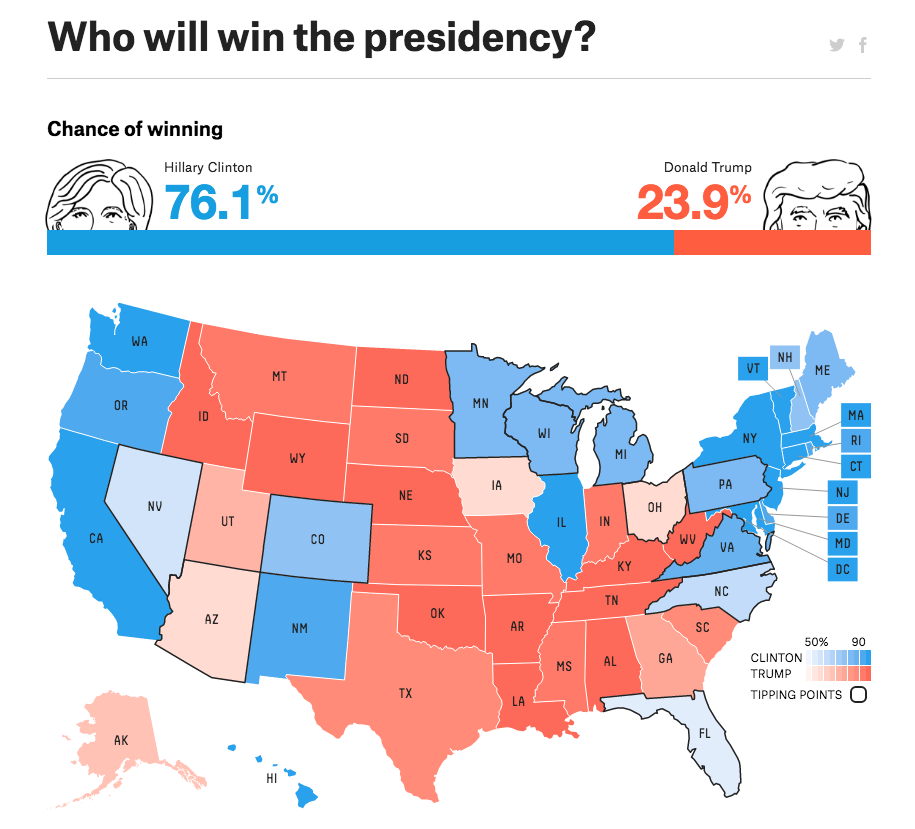 Roughly: it aggregates polls on a state-by-state basis, finding a probability of each candidate winning for each state. Then, it runs 20,000 (in the FiveThirtyEight case) computer simulations where each state’s outcome is determined by a random selection, weighted according this probability. Finally, the outcomes are tallied using the real election system (number of electors for each state) and a winner of each simulation is determined. The bottom line, referred to as “Chance of Winning”, is the percent of simulations in which each candidate was the winner. Despite being vastly superior to a nationwide poll, this method has huge issues when we’re trying to interpret its output. I’ll list a few:
Roughly: it aggregates polls on a state-by-state basis, finding a probability of each candidate winning for each state. Then, it runs 20,000 (in the FiveThirtyEight case) computer simulations where each state’s outcome is determined by a random selection, weighted according this probability. Finally, the outcomes are tallied using the real election system (number of electors for each state) and a winner of each simulation is determined. The bottom line, referred to as “Chance of Winning”, is the percent of simulations in which each candidate was the winner. Despite being vastly superior to a nationwide poll, this method has huge issues when we’re trying to interpret its output. I’ll list a few:
1. Simulated Probabilities for Rare Events Are Weird
Our brains are wired to interpret the world in a pretty binary way - phenomena and reasoning work that way: You either eat the cake or not. It either rained last Tuesday or it didn’t. A statement is either true or it’s false. The probability of something happening in the future - that’s not something we can accurately process. One way to think about the “chances of winning” is: we can put 100 colored balls into a bag. 76 are colored blue and 24 are colored red. We then shuffle the balls and pull one out without looking. The likelihood of pulling a blue ball is the likelihood of Clinton winning the election. Well, that should already trouble a Clinton supporter deeply: there’s nearly a 1 in 4 chance that pull out a red ball! This underlines a problem with thinking of a very rare and impactful event in terms of probability: there’s only one election every four years and the winner gets to command a huge nuclear weapons arsenal. All of a sudden a 76%, or even a 90% chance, doesn’t inspire that much confidence.
2. Probabilities Don’t Capture Change Over Time
Importantly, what this style of prediction fails to capture is the likelihood of changes to the prediction itself between now and the predicted event: One day the probability may be one thing, while the next day, when something happens in the world, it may change. Because of how we’re wired, when we look at a “chance of winning” like the above, we fail to factor in this “changeability”. It’s very hard to us even parse it: what does it mean about the eventual event we’re trying to predict that the prediction was 80%-20% yesterday and 75%-25% today? Which one is true and which one is false? Are both true? FiveThirtyEight does have a mode called “Polls Plus” which attempts to capture the likelihood of polls to be true or false based on historic data but any attempt in this direction will still fail to capture the entire complexity of human behavior leading to and on election day.
3. The spread in individual states appears much smaller than the spread in the overall chances
With an understanding of the electoral college system we can now drill down into key states and re alize that the difference between the candidates appears to be much smaller than in the bottom line prediction. As an example, let’s look at Florida: We see that even in polls where Clinton is winning, it’s only by a few points. A 44%-42% lead doesn’t sound as impressive as a “75% chance of winning”, does it?
alize that the difference between the candidates appears to be much smaller than in the bottom line prediction. As an example, let’s look at Florida: We see that even in polls where Clinton is winning, it’s only by a few points. A 44%-42% lead doesn’t sound as impressive as a “75% chance of winning”, does it?
4. Different State Polls Can End Up Being “Wrong” Together
One catalyst of the financial crisis of 2009 was Collateralized Mortgage Obligations (“CMO"s). The poorly executed idea was to group multiple subprime mortgages (those given to borrowers with a low credit score and are more likely to default) together as one investment product. They used statistics to claim these “packaged” mortgages carried a much lower risk together than any individual mortgage separately: if you run a simulation of how the loans will play out over their lifetimes, some borrowers will default but it’s unlikely that “many” of the mortgages will default, so the investor is still safe. The problem was obvious in hindsight: while the simulations assumed each mortgage is independent, in reality the underlying economic conditions that cause many borrowers to default are shared by all the mortgages. When borrowers started defaulting - a death spiral followed: they all defaulted, for the same reasons. Similarly, if there’s an underlying reason why polls would be skewed in one direction or another and/or if something will influence voters between now and election date - these things are likely to influence polls and voters in multiple states all at once. On paper, FiveThirtyEight tries to take this into account while admitting it’s “tricky”. My gut feeling, looking at the polls in individual swing states vs. the bottom line nationwide prediction, is that this phenomenon is not being accounted for enough to not be a problem.
5. This Time Polls Could Be Even Less Representative Than Usual
Let’s face it: the 2016 election is nothing short of extraordinary. No candidate in modern times was nearly as “unusual” as Trump. While all election polls contain errors of methodology:
- People change their minds
- Voters who were surveyed end up not voting
- A non-representative sample is used, for example because it’s easier to reach a certain type of people (e.g. older people who stay at home and answer the phone)
This time around, there’s even more cause for concern: Due to how controversial of a character Trump is, I find it very easy to imagine some voters unwilling to admit when polled on the phone that they’re voting for Trump. But that won’t prevent them from voting their heart on election day.